706 해시맵 디자인
706 해시맵 디자인
문제
Design a HashMap without using any built-in hash table libraries. To be specific, your design should include these functions:
- put(key, value) : Insert a (key, value) pair into the HashMap. If the value already exists in the HashMap, update the value.
- get(key): Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key.
- remove(key) : Remove the mapping for the value key if this map contains the mapping for the key.
조건
- $0 \le keys, values \le 1,000,000$
- $0 \le \text{The number of operations}\le 10,000$
- Please do not use the built-in HashMap library.
예제
MyHashMap hashMap = new MyHashMap();
hashMap.put(1, 1);
hashMap.put(2, 2);
hashMap.get(1); // returns 1
hashMap.get(3); // returns -1 (not found)
hashMap.put(2, 1); // update the existing value
hashMap.get(2); // returns 1
hashMap.remove(2); // remove the mapping for 2
hashMap.get(2); // returns -1 (not found)
해결
1st
1.1 해결해야 할 사항
- 예제를 보면 기본적인 딕셔녀리와 비슷해 보인다.
- 파이썬에 내장된 해시 테이블 라이브러리 사용하지 말 것. 그렇다면 내장된 해시 테이블 라이브러리는 뭐지?
- hashlib를 쓰지 말라는 건가?
- 파이썬에서 해시 테이블은? 결국 딕셔너리
Python’s dictionary implementation reduces the average complexity of dictionary lookups to O(1) by requiring that key objects provide a “hash” function
- 파이썬에서 dictionary 조회 과정은?
- 키의 해시 값은 hash 함수 사용하여 계산된다
- 해시 값은 key, value 쌍을 갖는
buckets또는충돌 리스트(collision lists)배열의 위치를 가리킨다 pair[0] == key에 해당하는 쌍을 찾을 때까지 해시 값이 가리키는충돌 리스트(collision lists)를 탐색하고, 해당 쌍의pair[1]을 반환
def lookup(d, key):
h = hash(key) # step 1
cl = d.data[h] # step 2: d.data는 `buckets` 또는 `충돌 리스트` 배열
for pair in cl: # step 3
if key == pair[0]: # pair는 tuple인가?
return pair[1]
else:
raise KeyError, "Key %s not found." % key
- 그렇다면 딕셔너리를 그대로 사용하는 게 아니라, 다른 방식 사용
1.2 생각
- 개별 체이닝과 오픈 어드레싱 두 가지 방식 사용 가능
- 개별 체이닝 시?
- 연결 리스트로 구현
- 해시는? mod 등 분산 방법 고려
- 오픈 어드레싱?
- Python처럼 버킷 또는 충돌 리스트에 저장하여 구현
- 해시는? 마찬가지로 고르게 분배
- 개별 체이닝으로 하고, 해시 방식을 좀 더 고려해보자
- 좋은 해시 함수들의 특징을 다시 상기
- 해시 함수 값 충돌의 최소화
- 고정 크기 값으로 변환하면서 같은 값이 나올 수 있기 때문
- 쉽고 빠른 연산
- 해시 테이블 전체에 해시 값이 균일하게 분포
- 사용할 키의 모든 정보를 이용하여 해싱
- 최대한 겹치지 않도록
- 해시 테이블 사용 효율이 높을 것
1.3 구현
1.3.1 hash function
- 무조건 복잡한 게 좋을까? 연산 속도를 고려하면 그렇지 않다. 목적은 빠르게 위치를 찾는 것
- dictionary가 아닌 array를 사용할 것이므로, 우선 인덱스를 구해야 한다
- 막연하니 자바를 참고해 보자
1.3.2 자바에서의 hash
HashTable.class
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
modCount++;
}
Array.class의 hashCode
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
String.class의 hashCode
/**
* String.class
*/
public int hashCode() {
// The hash or hashIsZero fields are subject to a benign data race,
// making it crucial to ensure that any observable result of the
// calculation in this method stays correct under any possible read of
// these fields. Necessary restrictions to allow this to be correct
// without explicit memory fences or similar concurrency primitives is
// that we can ever only write to one of these two fields for a given
// String instance, and that the computation is idempotent and derived
// from immutable state
int h = hash;
if (h == 0 && !hashIsZero) {
h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
if (h == 0) {
hashIsZero = true;
} else {
hash = h;
}
}
return h;
}
StringLatin1.class
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff); // 0xff = 255
}
return h;
}
StringUTF8.class
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
@HotSpotIntrinsicCandidate
// intrinsic performs no bounds checks
static char getChar(byte[] val, int index) {
assert index >= 0 && index < length(val) : "Trusted caller missed bounds check";
index <<= 1;
return (char)(((val[index++] & 0xff) << HI_BYTE_SHIFT) |
((val[index] & 0xff) << LO_BYTE_SHIFT));
}
- 자바에서는 해시 테이블의 인덱스 구하기 위해서
- 키 오브젝트의 hashCode() 정수 값을 가져오고
- 그 정수 값과
0x7FFFFFFF와 비트연산 후 테이블의 크기로 모듈러 연산
- 데이터 타입의 범위
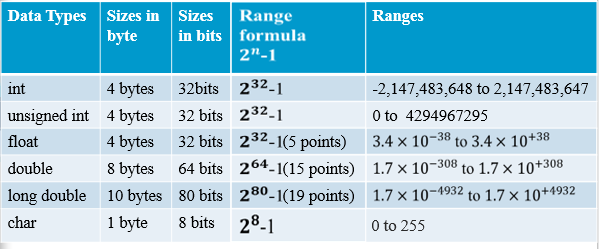
- 부호 있는 정수는 $-2^{31} \sim 2^{31} -1$
0x7FFFFFFF값은 10진수 2,147,483,647 정수를 16진수로 나타낸 것- 왜?
0x7FFFFFFF는 부호 비트를 제외한 32비트 정수 집합의 모든 비트를 가진다 111 1111 1111 1111 1111 1111 1111 1111로 총 31자리의 비트- 부호 비트가 없으므로
&연산 시 부호 비트는 0이 되며, 언제나 양의 정수가 된다
- 왜?
# https://myshell.co.uk/blog/2018/11/python-f-string-formatting-cheatsheet/
def print_bitwise(a, op = None, b = None):
print('============================================')
print("a: ", a, ",op: ", op, ",b: ", b)
if a:
a_in_64b = f"{a:64b}"
a_in_64b_len = str(len(a_in_64b) - a_in_64b.count(' '))
print(a_in_64b + " [" + a_in_64b_len + "]")
if b:
b_in_64b = f"{b:64b}"
b_in_64b_len = str(len(b_in_64b) - b_in_64b.count(' '))
print(b_in_64b + " [" + b_in_64b_len + "]")
if a and b and op:
print('--------------------------------------------')
if op == '&':
result = a & b
elif op == '|':
result == a | b
result_in_64b = f"{result:64b}"
result_in_64b_len = str(len(result_in_64b) - result_in_64b.count(' '))
print(result_in_64b + " [" + result_in_64b_len + "]")
print(f"{result:n}")
print_bitwise(222)
print_bitwise(-222)
print_bitwise(0x7FFFFFFF)
print_bitwise(-0x80000000)
print_bitwise(222, '&', 0x7FFFFFFF)
print_bitwise(2147483648, '&', 0x7FFFFFFF)
print_bitwise(98989898989898, '&', 0x7FFFFFFF)
print_bitwise(-222, '&', 0x7FFFFFFF)
'''
============================================
a: 222 ,op: None ,b: None
11011110 [8]
============================================
a: -222 ,op: None ,b: None
-11011110 [9]
============================================
a: 2147483647 ,op: None ,b: None
1111111111111111111111111111111 [31]
============================================
a: -2147483648 ,op: None ,b: None
-10000000000000000000000000000000 [33]
============================================
a: 222 ,op: & ,b: 2147483647
11011110 [8]
1111111111111111111111111111111 [31]
--------------------------------------------
11011110 [8]
222
============================================
a: 2147483648 ,op: & ,b: 2147483647
10000000000000000000000000000000 [32]
1111111111111111111111111111111 [31]
--------------------------------------------
0 [1]
0
============================================
a: 98989898989898 ,op: & ,b: 2147483647
10110100000011111100001110001000000000101001010 [47]
1111111111111111111111111111111 [31]
--------------------------------------------
1100001110001000000000101001010 [31]
1640235338
============================================
a: -222 ,op: & ,b: 2147483647
-11011110 [9]
1111111111111111111111111111111 [31]
--------------------------------------------
1111111111111111111111100100010 [31]
2147483426
'''
1.3.3 Python 코드로 구현
class MyHashMap:
PRIME = 31 # 문제의 키가 정수로만 넘어와서 사실 필요 없는 변수
TABLE_SIZE = 300
class ListNode:
def __init__(self, key = 0, value=0, next=None):
self.key = key
self.value = value
self.next = next
def __init__(self):
self.hash_table = [None] * self.TABLE_SIZE
"""
index와 key는 다르다!
"""
def put(self, key: int, value: int) -> None:
"""
value will always be non-negative.
"""
index = self.get_index(key)
head = self.hash_table[index]
if head is None:
self.hash_table[index] = self.ListNode(key, value)
return None
else:
# 새로운 리스트 노드를 앞에 붙여야 할까? 아니면 뒤에 붙여야 할까?
while head is not None:
if head.key == key:
# 키가 같으면 넘어온 값으로 치환하고 종료
head.value = value
return None
if head.next is not None:
head = head.next
else:
break
# next에 붙여 나갈 생각을 했는데, 오히려 가장 앞에 붙이는 게 더 편하다
# 새로운 노드를 "가장 앞"에 추가하여 hash_table에 삽입
self.hash_table[index] = self.ListNode(key, value, self.hash_table[index])
return None
def get(self, key: int) -> int:
head = self.hash_table[self.get_index(key)]
while head is not None:
if head.key == key:
return head.value
head = head.next
return -1
def remove(self, key: int) -> None:
index = self.get_index(key)
head = self.hash_table[index]
if head is None:
return None
else:
# key에 해당 하는 노드 제거
# 이전 노드와 다음 노드를 이어준다
# 첫번째 헤드에 해당하면 바로 다음 노드로 덮어 쓴다
if head.key == key:
self.hash_table[index] = head.next
return None
# https://www.geeksforgeeks.org/linked-list-set-3-deleting-node/
while head is not None:
if head.key == key:
break
node_prev = head
head = head.next
# AttributeError: 'NoneType' object has no attribute 'next'
# key에 해당하는 게 없으면 None일 수 있으므로, None 아닌 경우에만 삭제 처리
if head is not None:
node_prev.next = head.next
return None
# 정수만 들어오므로 테이블 크기로 모듈러 연산만 한다
def get_index(self, key: int):
return key % self.TABLE_SIZE
1.3.4 결과
- 테이블 크기가 증가하면 조금 더 빨라지긴 하지만, 큰 차이는 없다
TABLE_SIZE가 300일 경우
Runtime: 232 ms, faster than 62.98% of Python3 online submissions for Design HashMap. Memory Usage: 17.4 MB, less than 59.87% of Python3 online submissions for Design HashMap.
TABLE_SIZE가 1000일 경우
Runtime: 224 ms, faster than 68.99% of Python3 online submissions for Design HashMap. Memory Usage: 17.4 MB, less than 59.87% of Python3 online submissions for Design HashMap.