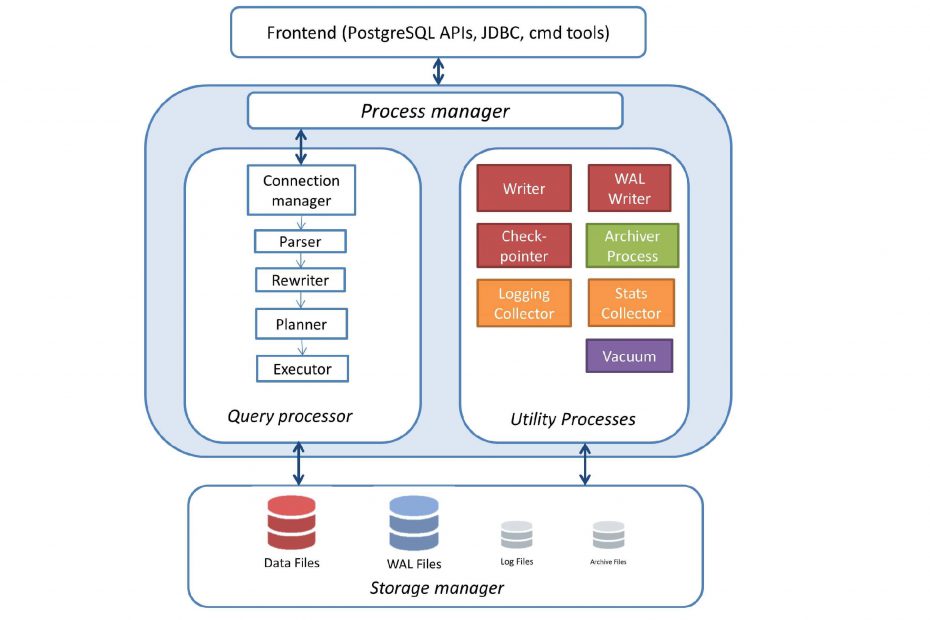
pgsql - 1. Architecture
개요
Shared Memory
Shared Buffer
- DISK I/O 최소화가 목적
- 매우 큰(수십, 수백 GB) 버퍼를 빠르게 액세스
- 많은 사용자 동시 접근 시 경합 최소화
- 자주 사용되는 블록은 최대한 오랫동안 버퍼 내 유지
- 백엔드 프로세스는 파일을 읽고 쓰는 게 아니라 버퍼와 램을 읽고 쓴다
postgresql.config파일의shared_buffers변수에 정해진 고정된 값의 메모리가 서버가 시작될 때 할당된다
WAL Buffer
개요
DB의 데이터 변경
$\to$ WAL 버퍼와 Data 버퍼 쓰기
$\to$ COMMIT 발생
$\to$ WAL 버퍼의 데이터를 디스크로 flush
$\to$ CHECKPOINT 발생
$\to$ 모든 데이터 버퍼를 디스크로 flush
WAL(Write-Ahead Log)? 말 그대로 로그를 남기고 데이터를 저장한다는 의미WAL Buffer? 데이터베이스의 변경 사항을 잠시 저장하는 버퍼- 매번 모든 커밋을 바로 파일에 쓰지 않기 때문에 성능 향상
- 모든 변화는 WAL 파일에 기록되므로 장애 시에도 복구가 용이하다
CHECKPOINT
CHECKPOINT?- 만약 DB가 모든 데이터 변경 사항이 디스크로 flush된 WAL 로그의 위치를 보장할 수 있다면? 장애 복구 시 나머지 WAL 부분에 대해서만 replay를 하면 된다
- 체크포인트는 특정 시점 이전의 WAL에 대한 복구가 더이상 필요치 않음을 보장한다
- 이를 통해 디스크 공간 요구사항과 복구 시간을 줄일 수 있다
CHECKPOINT발생 시점?CHECKPOINT명령어 실행CHECKPOINT를 필요로 하는 명령 실행(pg_start_backup,pg_ctl start|restart등)checkpoint_timeout시간에 도달max_wal_size가 가득찬 경우
CHECKPOINT발생 시 DB는 다음 세 단계 수행- shared buffer에 dirty block(수정된 블록)이 있는지 찾는다
- 모두 디스크(또는 파일 시스템 캐시)에 쓰기
- 모든 수정된 파일들을 디스크에
fsync()
checkpoint_timeout 조회
postgres=# SHOW checkpoint_timeout;
checkpoint_timeout
--------------------
5min
(1개 행)
checkpoint_completion_target
- 대량의 페이지 쓰기가 갑작스럽게 이뤄져서 I/O 부하가 발생하는 것을 피하기 위한 설정
checkpoint_timeout이 5min,checkpoint_completion_target가 0.5면?- DB는 마지막 쓰기가 2.5분 뒤에 이뤄지도록 쓰기를 제한(throttle)
- OS는 데이터를 디스크에 쓸 2.5분이 더 생기고
fsync()는 그만큼 비용이 저렴해지고 빨라진다
max_wal_size 조회
postgres=# SHOW max_wal_size;
max_wal_size
--------------
1GB
(1개 행)
Dynamic WAL Switching
- pg 9.6 버전부터 도입된 모델
단일 WAL 파일이 가득 차고(기본 16MB) 남은 디스크 공간이 부족해질 때까지 WAL log 쓰기
$\to$ 다음 쓰기를 위해 오래된 WAL 파일 사용
프로세스
[root@vultr ~]# systemctl status postgresql-13
● postgresql-13.service - PostgreSQL 13 database server
Loaded: loaded (/usr/lib/systemd/system/postgresql-13.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2021-07-22 23:26:23 KST; 2s ago
Docs: https://www.postgresql.org/docs/13/static/
Process: 3794307 ExecStartPre=/usr/pgsql-13/bin/postgresql-13-check-db-dir ${PGDATA} (code=exited, status=0/SUCCESS)
Main PID: 3794313 (postmaster)
Tasks: 8 (limit: 49532)
Memory: 30.6M
CGroup: /system.slice/postgresql-13.service
├─3794313 /usr/pgsql-13/bin/postmaster -D /var/lib/pgsql/13/data/
├─3794314 postgres: logger
├─3794316 postgres: checkpointer
├─3794317 postgres: background writer
├─3794318 postgres: walwriter
├─3794319 postgres: autovacuum launcher
├─3794320 postgres: stats collector
└─3794321 postgres: logical replication launcher
[root@vultr ~]# pstree -p 3794313
postmaster(3794313)─┬─postmaster(3794314)
├─postmaster(3794316)
├─postmaster(3794317)
├─postmaster(3794318)
├─postmaster(3794319)
├─postmaster(3794320)
└─postmaster(3794321)
Postmaster
- PostgreSQL 기동 시 가장 먼저 시작되는 프로세스
- 모든 프로세스의 부모 프로세스
- 문서상으로는 deprecate된
postgres의 alias라고 한다
[root@vultr ~]# ll /usr/pgsql-13/bin/postmaster
lrwxrwxrwx. 1 root root 8 5월 18 22:23 /usr/pgsql-13/bin/postmaster -> postgres
postgres
- PostgreSQL 데이터베이스 서버
- 하나의
postgres는 공통된 파일 시스템 경로(“data area”)에 저장되는 데이터베이스 집합인 데이터베이스 클러스터 한 개를 관리 - 여러 데이터베이스 클러스터가 서로 다른 data area와 통신 포트를 사용할 경우, 여러
postgres인스턴스가 한 시스템에서 실행될 수 있다 -D옵션 또는PGDATA환경변수로 반드시 data area 영역이 지정되어야 한다
postgres가 하는 일?
- 초기 기동 시
- 복구 작업
- Shared 메모리 초기화 작업
- 백그라운드 프로세스 구동 작업
- 클라이언트 프로세스의 접속 요청 시 Backend 프로세스 생성
Background
- pgsql 운영에 필요한 백그라운드 프로세스
logger
- 에러 메시지를 로그 파일에 기록
checkpointer
- 체크포인트 발생 시 dirty 버퍼를 파일에 기록
background writer
- 주기적으로 dirty 버퍼를 파일에 기록
wal writer
- WAL 버퍼 내용을 WAL 파일에 기록
autovacuum launcer
Vacuum필요 시점에autovacuum worker를 fork
archiver
- Archive log 모드일 때, WAL 파일을 지정된 디렉토리에 복사
stats collector
- DBMS 사용 통계 정보 수집
pg_stat_activity: 세션 수행 정보pg_stat_all_tables: 테이블 사용 통계 정보
Backend
- 사용자 프로세스의 쿼리 요청 수행 후 결과 전송 역할 수행
max_connections파라미터로 최대 개수 설정 가능
work_mem 파라미터
- 다음과 같이 복잡한 쿼리 등의 작업이 있는 경우 사용되는 공간
- 정렬 작업
- Bitmap 작업
- 해시 조인 작업
- Merge 조인 작업 등
- 기본 설정 값은 4MiB
maintenance_work_mem 파라미터
- 말 그대로 관리를 위한 작업에 사용되는 메모리 공간 설정 값
VacuumCREATE INDEXALTER TABLE ADD FOREIGN KEY등
- 기본 설정 값은 64MiB
temp_buffers 파라미터
- 각 데이터베이스 세션 내의 temporary buffer가 사용하는 메모리 공간
- 이 session-local 버퍼는 temporary table 접근할 때만 사용
- 세션은 필요 시
temp_buffers의 값에 따라 임시 버퍼를 할당 - 단위 없이 지정된 경우,
BLCKSZ바이트인 블록으로 받아들여지며,BLCKSZ는 일반적으로 8kB(8192 bytes)(즉, 단위가 블록이 된다는 의미인 듯) - 기본 설정값은 8MiB가 되고,
BLCKSZ가 8kB가 아니면 기본값은 그 값에 비례하여 조정된다
Client
- 접속, 쿼리 등 요청
참고 링크
데이터베이스 구조
데이터베이스 관련 사항
- pgsql은 여러 데이터베이스로 구정되고, 이를 데이터베이스 클러스터라고 한다
initdb()수행 시template0,template1,postgres데이터베이스 생성
template0, template1?
- 사용자 데이터베이스 생성 위한 템플릿 데이터베이스
- 시스템 카탈로그 테이블 포함
template0,template1의 테이블 목록은 같다template1데이터베이스에는 사용자가 필요한 오브젝트 생성 가능template1사용하여 사용자 데이터베이스 생성
테이블스페이스 관련 사항
initdb()수행 직후pg_default,pg_global테이블스페이스 생성된다- 1개의 테이블스페이스를 여러 개의 데이터베이스가 사용 가능. 테이블스페이스 디렉토리 내에 데이터베이스별 서브 디렉토리 생성
pg_default
- 테이블 생성 시 테이블스페이스 지정하지 않으면
pg_default에 저장 - 물리적 위치:
$PGDATA/base
pg_global
- 데이터베이스 클러스터 레벨에서 관리되는 테이블은
pg_global에 저장 - 물리적 위치:
$PGDATA/global
사용자 테이블 스페이스
- 물리적 위치에 사용자 테이블스페이스와 관련된 심볼릭 링크 생성된다
- 물리적 위치:
$PGDATA/tblspc
테이블 관련 사항
- 테이블별로 3개의 파일이 존재
OIDOID_fsmOID_vm
- 인덱스는? _vm 파일이 없다.
OIDOID_fsm
- 주의 사항
- 테이블 & 인덱스 생성 시점의 파일명 =
OID=pg_class.relfilenode - Rewrite 작업(
Truncate,CLUSTER,Vacuum Full,REINDEX등) 수행 $\to$ 영향받은 오브젝트의relfilenode값 변경 $\to$ 파일명도relfilenode값으로 변경 pg_relation_filepath('오브젝트명')명령어로 파일 위치와 이름 쉽게 확인 가능
- 테이블 & 인덱스 생성 시점의 파일명 =
테이블 데이터 저장 파일
- 파일명: 테이블의
OID
테이블 여유 공간 관리 파일
- 파일명:
OID_fsm
테이블 블록 visibility 관리 파일
- 파일명:
OID_vm
template0, template1 postgres 데이터베이스
pg_database뷰 조회
SELECT
oid,
datname,
datistemplate,
datallowconn
FROM pg_database
ORDER BY 1;
oid | datname | datistemplate | datallowconn
-------+-----------+---------------+--------------
1 | template1 | t | t
13437 | template0 | t | f
13438 | postgres | f | t
(3개 행)
datistemplate? 사용자 데이터베이스 생성 위한 template용 데이터베이스 의미datallowconn? 데이터베으스 접속 가능 여부- 템플릿은 왜 2개?
template0: 초기 상태 템플릿을 제공template1:tmplate0+ 사용자 추가 오브젝트
postgres?template1이용해서 생성된 기본 데이터베이스.- 접속 시에 데이터베이스 지정하지 않으면
postgres데이터베이스로 접속
- 기본 데이터베이스들로
pg_default테이블스페이스에 저장되며, 물리적 위치는$PGDATA/base다
SELECT
a.oid,
a.datname,
a.datistemplate,
a.datallowconn,
a.datconnlimit,
a.dattablespace,
b.spcname
FROM pg_database a
JOIN pg_tablespace b
ON b.oid = a.dattablespace;
oid | datname | datistemplate | datallowconn | datconnlimit | dattablespace | spcname
-------+-----------+---------------+--------------+--------------+---------------+------------
13438 | postgres | f | t | -1 | 1663 | pg_default
1 | template1 | t | t | -1 | 1663 | pg_default
13437 | template0 | t | f | -1 | 1663 | pg_default
$PGDATA/base내용을 보면OID와 일치하는 디렉토리가 있음을 볼 수 있다.
# systemctl show -p Environment postgresql-13.service
Environment=PGDATA=/var/lib/pgsql/13/data/ PG_OOM_ADJUST_FILE=/proc/self/oom_score_adj PG_OOM_ADJUST_VALUE=0
[root@vultr ~]# ll /var/lib/pgsql/13/data/base/
합계 12
drwx------. 2 postgres postgres 4096 7월 21 21:31 1
drwx------. 2 postgres postgres 4096 7월 21 21:31 13437
drwx------. 2 postgres postgres 4096 7월 24 01:07 13438
- 구조
tmplate0 tmplate1 사용자db
[template0] [template0] [template1]
[템플릿추가] [사용자 오브젝트]
사용자 DB 생성
– template 데이터베이스에 접속하여 사용자 테이블 t1을 생성
postgres=# \c template1
접속정보: 데이터베이스="template1", 사용자="postgres".
template1=# CREATE TABLE t1 (c1 INTEGER);
CREATE TABLE
template1=# \d+ t1
"public.t1" 테이블
필드명 | 종류 | Collation | NULL허용 | 초기값 | 스토리지 | 통계수집량 | 설명
--------+---------+-----------+----------+--------+----------+------------+------
c1 | integer | | | | plain | |
접근 방법: heap
- 사용자 데이터베이스 생성 후 테이블 확인해보면
template1에서 생성했던t1테이블 복제된 것 확인 가능
postgres=# CREATE DATABASE db_aimpugn;
CREATE DATABASE
postgres=# \c db_aimpugn
접속정보: 데이터베이스="db_aimpugn", 사용자="postgres".
db_aimpugn=# \dt+
릴레이션(relation) 목록
스키마 | 이름 | 종류 | 소유주 | Persistence | 크기 | 설명
--------+------+--------+----------+-------------+---------+------
public | t1 | 테이블 | postgres | permanent | 0 bytes |
(1개 행)
pg_global 테이블스페이스
데이터베이스 클러스터레벨에서 관리해야 할 데이터들을 저장. 어떤 db에서 조회해도 동일 정보 제공.pg_databasepg_authid등
사용자 테이블스페이스 생성
- 디렉토리는 만들어주지 않으며, 반드시 존재해야 한다.
[root@vultr home]# mkdir /home/data
[root@vultr home]# chown -R postgres:postgres /home/data
- 임의의 테이블스페이스를 생성
-- 경로는 절대경로 지정해야 한다
postgres=# CREATE TABLESPACE tspc_aimpugn LOCATION '/home/data';
CREATE TABLESPACE
$PGDATA/pg_tblspce에 심볼릭 링크가 생성
[root@vultr home]# ll $PGDATA/pg_tblspc
합계 0
lrwxrwxrwx. 1 postgres postgres 10 7월 25 17:38 16396 -> /home/data
사용자 테이블스페이스와 사용자 테이블
postgres데이터베이스
db_aimpugn=# \c postgres
접속정보: 데이터베이스="postgres", 사용자="postgres".
postgres=# CREATE TABLE t1 (c1 INTEGER) TABLESPACE tspc_aimpugn;
CREATE TABLE
postgres=# SELECT oid FROM pg_class WHERE relname = 't1';
oid
-------
16398
(1개 행)
db_aimpugn데이터베이스
-- 이미 t1 테이블 있음
db_aimpugn=# CREATE TABLE t1 (c1 INTEGER) TABLESPACE tspc_aimpugn;
오류: "t1" 이름의 릴레이션(relation)이 이미 있습니다
db_aimpugn=# \d+ t1
"public.t1" 테이블
필드명 | 종류 | Collation | NULL허용 | 초기값 | 스토리지 | 통계수집량 | 설명
--------+---------+-----------+----------+--------+----------+------------+------
c1 | integer | | | | plain | |
접근 방법: heap
db_aimpugn=# DROP TABLE t1;
DROP TABLE
db_aimpugn=# CREATE TABLE t1 (c1 INTEGER) TABLESPACE tspc_aimpugn;
CREATE TABLE
db_aimpugn=# \d+ t1
"public.t1" 테이블
필드명 | 종류 | Collation | NULL허용 | 초기값 | 스토리지 | 통계수집량 | 설명
--------+---------+-----------+----------+--------+----------+------------+------
c1 | integer | | | | plain | |
테이블스페이스: "tspc_aimpugn"
접근 방법: heap
-- OID 확인
db_aimpugn=# SELECT oid FROM pg_class WHERE relname = 't1';
oid
-------
16401
(1개 행)
tspc_aimpugn테이블스페이스의 공간인/home/data을 확인해 보면
[root@vultr data]# tree
.
└── PG_13_202007201
├── 13438 // postgres
│ └── 16398 // t1
└── 16397 // db_aimpugn
└── 16401 // t1
테이블스페이스 > DB > 테이블뎁스로 형성됨을 확인할 수 있다
oid | datname | datistemplate | datallowconn | datconnlimit | dattablespace | spcname
-------+------------+---------------+--------------+--------------+---------------+------------
13438 | postgres | f | t | -1 | 1663 | pg_default
1 | template1 | t | t | -1 | 1663 | pg_default
13437 | template0 | t | f | -1 | 1663 | pg_default
16397 | db_aimpugn | f | t | -1 | 1663 | pg_default
테이블스페이스 LOCATION 변경 방법
- pgsql의 테이블스페이스는 디렉토리 지정 방식으로, 해당 디렉토리의 용량이 가득 차면 더 이상 데이터 저장할 수 없는데, 이런 문제 해결 위해서는
볼류 매니저이용 - 작업 순서
- pgsql 종료
systemctl stop postgresql-13 - 테이블스페이스 LOCATION을 새로운 파일시스템으로 복사
cp -rp /home/data/PG* <새경로> - pg_tblspc 디렉토리 내용 확인
ll $PGDATA/pg_tblpsc - 심볼릭 링크 삭제
rm 12345 - 새로운 심볼릭링크 생성
ln -s <새경로> 12345 - 내용 확인
ll $PGDATA/pg_tblpsc - pgsql 재시작
systemctl start postgresql-13
- pgsql 종료
VACUUM
하는 일?
- 테이블 및 인덱스 통계 정보 수집(일반 DBMS 작업)
- 테이블 재구성(일반 DBMS 작업)
- 테이블 및 인덱스 DEAD 블록 정리(pgsql MVCC 특징 때문에 필요한 작업)
- XID Wraparound 방지 위한 레코드별 XID Frozen(pgsql MVCC 특징 때문에 필요한 작업)
ORACLE vs PostgreSQL
- 가장 큰 차이점은 MVCC 모델 구현 방식과 Shared Pool 존재 여부
| 항목 | ORACLE | PostgreSQL |
|---|---|---|
MVCC 모델 구현 방식 |
UNDO 세그먼트 | 블록 내에 이전 레코드 저장 |
| Shared Pool 존재 여부 | 존재 | 존재하지 않음 |
MVCC 모델의 차이점
- 동시성 높이기 위해서는 다음 원칙을 지켜야 한다
- 읽기 작업은 쓰기 작업을 블로킹하지 않고
- 쓰기 작업은 읽기 작업을 블로킹하지 않아야 한다
MVCC?- Multi Version Concurrency Control
- 동시성 높이기 위한 원칙 구현에 필요
Shared Pool 존재 여부
- PostgreSQL은 Shared Pool 대신 프로세스 레벨에서 SQL 정보를 공유하는 기능을 제공
- 하나의 프로세스에서 같은 SQL을 여러 번 수행하면 최초 1회만 하드 파싱